Maschinelles Lernen: Delta-Regel nach Rosenblatt
Kommen wir nun zu der eigentlichen Stärke von Perzeptronen, dem so genannten maschinellen Lernen, durch das sich Perzeptronen ganz prinzipiell von herkömmlichen Algorithmen entscheiden.
Die Gewichte und Schwellenwerte von Perzeptronen mühsam per Hand zu justieren wäre sehr arbeitsaufwendig. Daher hat Rosenberg 1958 einen Algorithmus entwickelt, mit dessen Hilfe die Gewichte und Schwellenwerte von Perzeptronen automatisiert mittels so genannter Trainingsdaten bestimmt werden können. Dazu werden die Gewichte und Schwellenwerte zu Beginn des Lernprozesses einfach mit Zufallszahlen belegt und dann iterativ mittels vorklassifizierter Trainingsdaten sukzessive verbessert.
Um bei dem Beispiel mit den Tieren zu bleiben, kann man sich vorstellen, dass es eine Menge von Tieren gibt, die durch Menschen als gefährlich bzw. ungefährlich klassifiziert worden sind. Mit diesen Trainingsdaten werden Gewichte und Schwellenwert eines Perzeptron nun so trainiert (also sukzessive angepasst), dass das Perzeptron anschließend selbständig weitere, ihm bisher unbekannte, Tiere als gefährlich bzw. ungefährlich klassifizieren können soll.
Um den Lernalgorithmus nach Rosenblatt detailliert zu erläutern, betrachten wir zunächst wieder ein Perzeptron mit zwei Eingängen. Zur Veranschaulichung kann man sich vorstellen, dass es sich dabei wieder um die beiden Merkmale Zahn- und Augengröße handelt:
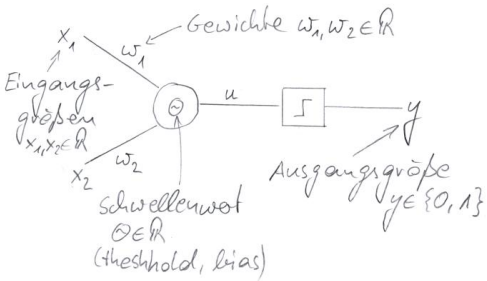
Statt die Gewichte $\vec{w}$ und den Schwellewenwert $\Theta$ mühsam per Hand zu justieren, soll das Perzeptron nun wie bereits gesagt selbständig lernen, auf bestimmten Eingangsgrößen $\vec{x}$ mit einer jeweils vorgegebenen Ausgangsgröße $y \in \{0,1\}$ zu reagieren. Der dazu verwendete Lernalgorithmus nach Rosenblatt wird zunächst in Pseudocode angegeben, im Anschluß daran wird die Funktionsweise des Algorithmus dann auch noch graphisch veranschaulicht.
Sei eine Menge an Eingabevektoren $\Omega$ gegeben, die in zwei disjunkte Teilmengen $\Omega = \Omega_P \cap \Omega_N$ zerfällt. Für einen Eingabevektor $\vec{x} \in \Omega_P$ soll das Perzeptron feuern ($y=1$), für einen Eingabevektor $\vec{x} \in \Omega_N$ soll es nicht feuern ($y=0$). Um bei dem gewählten Beispiel zu bleiben, kann man sich vorstellen, dass $\Omega_P$ die Menge der gefährlichen und $\Omega_N$ die Menge der ungefährlichen Tiere darstellt.
Anschaulich formulierter Lern-Algorithmus nach Rosenblatt:
start:wähle $\vec{w}(0) \in \mathbb{R}^2$ zufällig (Startgewichte)
wähle $\Theta(0) \in \mathbb{R}$ zufällig (Startschwellenwert)
setzte $t := 0$
test:
Solange noch nicht ausgewählt $\vec{x}$
und solange noch nicht alle $\vec{x}$ das gewünschte Ergebnis $y$ liefern,
wähle $\vec{x} \in \Omega$ zufällig
if $\vec{x} \in \Omega_P$ and $y=1$ then goto test
if $\vec{x} \in \Omega_N$ and $y=0$ then goto add
if $\vec{x} \in \Omega_N$ and $y=0$ then goto test
if $\vec{x} \in \Omega_P$ and $y=1$ then goto sub
add:
setzte $\vec{w}(t+1) := \vec{w} (t) + \vec{x}$
setzte $\Theta(t+1) := \Theta (t) +1$
setzte $t := t+1$
goto test
sub:
setzte $\vec{w}(t+1) := \vec{w} (t) - \vec{x}$
setzte $\Theta(t+1) := \Theta (t) - 1$
setzte $t := t+1$
goto test
Geometrische Veranschaulichung des Lernalgorithmus
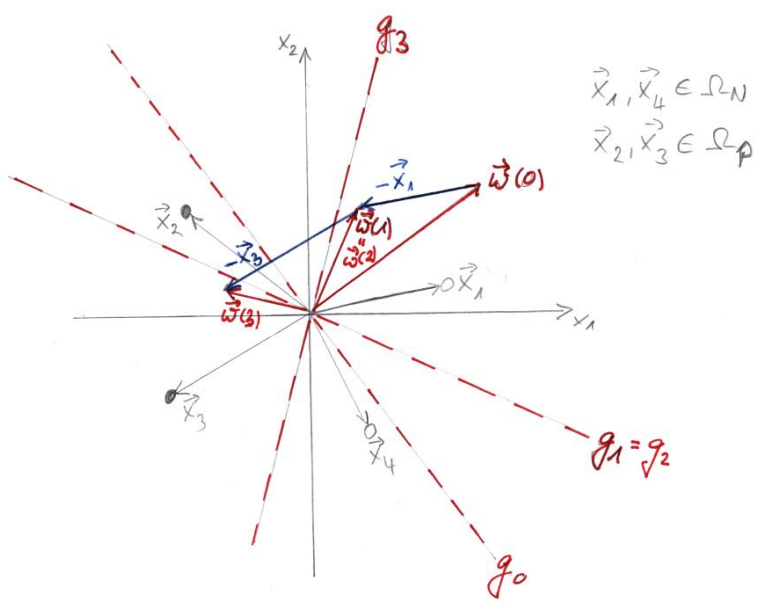 Durch den Lernalgorithmus wird der Gewichtsvektor wie in der Abbildung gezeigt sukkzessive gedreht, bis schließlich alle Eingangsvektoren $\vec{x}$ korrekt klassifiziert werden. Beachte jedoch, dass die Abbildung insofern unvollständig ist, als die Updateregeln für den Schwellenwert $\Theta$ nicht berücksichtigt wurden. (Die tatsächlichen Separationsgeraden liegen bei Berücksichtigung der jeweiligen Werte von $\Theta$ daher lediglich parallel zu den eingezeichneten Geraden $g_1, g_2$ und $g_3$.)
Durch den Lernalgorithmus wird der Gewichtsvektor wie in der Abbildung gezeigt sukkzessive gedreht, bis schließlich alle Eingangsvektoren $\vec{x}$ korrekt klassifiziert werden. Beachte jedoch, dass die Abbildung insofern unvollständig ist, als die Updateregeln für den Schwellenwert $\Theta$ nicht berücksichtigt wurden. (Die tatsächlichen Separationsgeraden liegen bei Berücksichtigung der jeweiligen Werte von $\Theta$ daher lediglich parallel zu den eingezeichneten Geraden $g_1, g_2$ und $g_3$.)
Zusammenfassung des Lernalgorithmus in einer einzigen Lernregel
Betrachte einen Eingangsvektor $\vec{x} \in \Omega$. Sei $Y(\vec{x})$ die zugehörige Sollausgabe, also \begin{eqnarray} Y(\vec{x}) := \left\{\begin{array}{ll} 1 & \vec{x} \in \Omega_P \\ 0 & \vec{x} \in \Omega_N \end{array}\right. , \nonumber \end{eqnarray} und setzte $\delta := Y(\vec{x}) - y(\vec{x})$ als die Abweichung von $y$ von der Sollausgabe $Y$. Dann lassen sich die Unterfälle des obigen Lernalgorithmus elegant zusammenfassen zu je einer einzigen Lernregel für $\vec{w}$ und für $\Theta$ als \begin{eqnarray} \vec{w}(t+1) &:=& \vec{w}(t) + \delta \vec{x} \nonumber \\ &=& \vec{w}(t) + (Y-y) \vec{x} \nonumber \\ \Theta(t+1) &:=& \theta(t) + \delta\cdot (-1) \nonumber \\ &=& \theta(t) - \delta \nonumber \end{eqnarray} Meist wird noch eine so genannte Lenrate $\eta>0$ (Lerngeschwindigkeit) eingeführt, so dass man als Lernregel für Perzeptronen erhält: \begin{eqnarray} \vec{w}(t+1) &:=& \vec{w}(t) + \eta (Y-y) \vec{x} \nonumber \\ \Theta(t+1) &:=& \theta(t) - \eta \delta \nonumber \end{eqnarray} Wenn die Menge $\Omega$ eine sehr große Menge Eingangsvektoren enthält, wird sie oft aufgeteilt in zwei disjunkte Teilmengen \begin{eqnarray} \Omega_L &:& \textrm{learning batch} \nonumber \\ \Omega_T &:& \textrm{testing batch} \nonumber \end{eqnarray}Die Teilmenge $\Omega_L$ wird dann zum Trainieren des Perzeptrons nach der Lernregel verwendet, während die anderen Teilmenge $\Omega_T$ zum anschließenden Testen verwendet wird, um herauszufinden, wie gut die Gewichte und der Schwellenwert des Perzeptrons justiert wurden. Oft wird das zahlenmäßiges Verhältnis von $\#\Omega_L : \#\Omega_T$ als $80\% : 20\%$ gewählt.
Abschließend wird die obige Lernregel noch auf den Fall von $n$-dimensionalen Eingangsvektoren erweitert, so dass man den vollständigen Lernalgorithmus erhält als:
Lernalgorithmus für Perzeptronen
start:wähle $\vec{w}(0) \in \mathbb{R}^n$ zufällig (Startgewichte)
wähle $\Theta(0) \in \mathbb{R}$ zufällig (Startschwellenwert)
wähle $\eta > 0$ (Lernrate)
setzte $t := 0$
step:
wähle $\vec{x} \in \Omega_L$
if $\vec{x} \in \Omega_P$ setze $Y:=1$
if $\vec{x} \in \Omega_N$ setze $Y:=0$
berechne $y(\vec{x}) = f_\theta(\vec{w}\cdot\vec{x})$ (Ausgabegröße)
berechne $\delta = Y - y$ (Fehler)
update $\vec{w}(t+1) := \vec{x}(t) + \eta \delta \vec{x}$
update $\Theta(w+1) := \Theta(t) - \eta \delta$
setzte $t := t+1$
end:
Solange es noch $\vec{x} \in \Omega_L$ gibt mit $\delta \ne 0$ goto step
Anmerkung
Wird der Schwellenwert $\Theta$ wie oben beschrieben in den Gewichtsvektor integriert, so fällt in dem obigen Algorithums die entsprechenden Zeile zum Update des Schwellenwertes $\Theta$ weg, da es dann bereits automatisch in dem Update des Gewichtsvektors enthalten ist.
Rosenblatt hat 1958 gezeigt, dass der obige Algorithmus terminiert, falls die Menge der Eingabegrößen separierbar ist. Auf die Wiedergabe des Beweises wird an dieser Stelle verzichtet.
Anwendung auf neue Eingabegrößen
Nachdem das Perzeptron mit Hilfe der obigen Lernregel trainiert worden ist, kann es anschließend auch auf Eingabevektoren $\vec{x} \notin \Omega$ angewandt werden, die gar nicht in der ursprünglichen Menge $\Omega$ enthalten waren und für die die tatsächliche Ausgabegröße $Y$ daher unter Umständen noch unbekannt ist. In diesem Sinne stellt $y(\vec{x})$ dann eine Vorhersage für den tatsächlichen Wert $Y(\vec{x})$ dar.
Man beachte jedoch, dass es sich dabei lediglich um eine Vorhersage handelt, die sich (mit einer gewissen Wahrscheinlichkeit) bei näherer Analyse dann aber durchaus auch als falsch erweisen kann. In dem oben gewählten Beispiel könnte das bedeuten, dass das Perzeptron ein Tier als ungefährlich einstuft, während es sich in Wirklichkeit um ein äußerst gefährliches Tier handelt. Zum Beispiel könnte das Tier weder große Zähne noch große Augen haben aber trotzdem hochgiftig sein. Ein blindes Vertrauen auf die Vorhersage des Perzeptrons könnte abhängig vom Anwednungsszenario also sehr dramatische Konsequenzen haben.
Bedeutung der Trainingsdaten
Im Unterschied zu herkömmlichen Algorithmen ist für automatisiertes maschinelles Lernen die Verfügbarkeit von vorklassifizierte Trainingsdaten unerlässlich. Ohne solche Trainingsdaten kann der oben beschriebene Lern-Algorithmus zwar implementiert, aber nicht trainiert werden.
Damit liegt die Kontrolle solcher maschinell lernenden Algorithmen bei denjenigen, die Zugriff auf geeignete vorklassifizierten Daten haben. Vor diesem Hintergrund wird auch verständlich, warum es heute so lukrativ geworden ist, möglichst viele Daten über möglichst viele Menschen zu sammeln.